
The Business Case for Implementing Data Lake

Two broad trends are driving the case for implementing Data Lakes in organizations: popularity of Cloud based storage which is driving down cost of storing petabytes of data; and growth of machine-generated unstructured data from mobiles, devices, IoT which can be combined with structured data to get powerful business insights.
Most organizations do not have a comprehensive data strategy, using data in isolation and missing out on the big picture. Data Lake fills this gap by providing a data strategy which benefits all groups within the organization to get new insights into operations and opportunities.
So what exactly is a Data Lake? It is a single source of truth comprising vast amounts of structured and unstructured data from a variety of sources, including raw copies of source data and transformed data which can be used for reporting, visualization and analytics.
Data Lakes ingests data very quickly and prepares it for usage—a key activity being to organize data from different sources, otherwise it quickly becomes a Data Swamp.
Setting up Data Lake Has Become Easy
The rising popularity of Data Lake is because Cloud provides a cost-effective way of storing and cataloguing data. AWS Cloud provides the scale and a supporting ecosystem of open-source tools as managed service to build Data Lake.
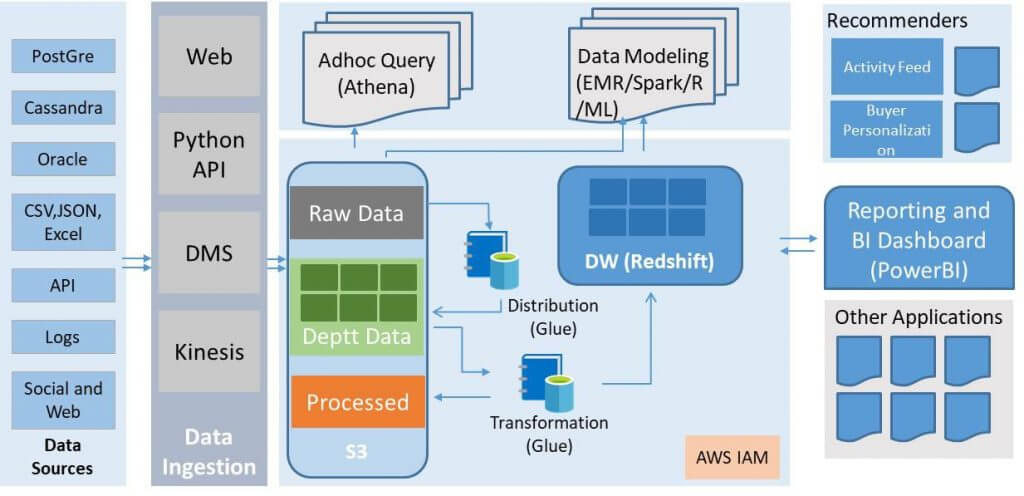
- S3: Customers can achieve huge savings by separating storage and compute. For example, you can store large data sets in the highly scalable S3 at minimal cost, and run queries using AWS Athena paying only for queries you run.
- Athena: Athena queries both structured and unstructured data in S3 and being serverless, you can start analysing data almost immediately after defining the schema and visualize output using Amazon QuickSight.
- AWS Glue: If you need to extract and transform data, you can use Amazon Glue—a fully managed serverless service which automatically discovers properties in data via Catalog engine and generate ETL code to transform source code into target schemas.
- AWS EMR: Open sourced tools such as Hadoop, Hive, Spark have become easily available as managed services on AWS EMR clusters to run big data workloads.
- AWS Redshift: You can extend your data warehouse to the Data Lake and get powerful insights which you cannot by querying independent silos. Using Spectrum, a feature in Redshift you can directly query open data formats stored in S3 without moving data.
In contrast storing petabytes of data using a database or warehouse is expensive as you need to factor in cost of licence, storage and equivalent compute cost. Also there is the constraint of time and effort as data that goes into must be cleansed and prepared before storing, which is not feasible with tons and tons of unstructured data—without guarantee that all data will be used. Considering that unstructured data spans anything from social media to machine data such as logs and sensor data, processing all data requires careful consideration.
Data Lake Architecture in AWS Cloud
Use Cases for Data Lake
- Reports and Dashboard: Reports and dashboards on operations, customer preferences, etc become more powerful with insights from integrated data across channels and multiple engagement points.
- Advanced Analytics such as recommendation Engine: Optimize search and provide more meaningful recommendation to users by analyzing customer queries and tracking preferences across all touch points.
- Ad-hoc queries for management reports: Supplement decision making and hypothesis with quick queries into comprehensive pool of data.
- Large report generation and batch processing: Create extensive, detailed reports continuously to achieve operational excellence, thwart threats, take advantage of opportunities in real-time.
- Pattern finding using ML algorithms: Spot trends and make predictions with large, heterogenous data sets using machine learning.
Umbrella has helped many organizations reap the benefits of a comprehensive data strategy by implementing Data Lake with robust extraction, loading and transformation methodologies. If you are interested in knowing more about a data strategy or want to implement a Data Lake, reach out to us.





